So, this is the first part of the series on how to read an execution plan. In this post, I’m going to give a high-level overview of how the execution plan looks and how, in general, to read it.
For the purposes of this and other posts in this series, all screenshots will be from SQL Management Studio (the 2005 GUI) and all comments on features will refer to that tool. Query Analyser, from SQL 2000, is very similar. For other querying tools, your mileage may vary.
Here’s a very simple execution plan. The query that produced this plan is just a join of three tables in the AdventureWorks database on SQL 2005.
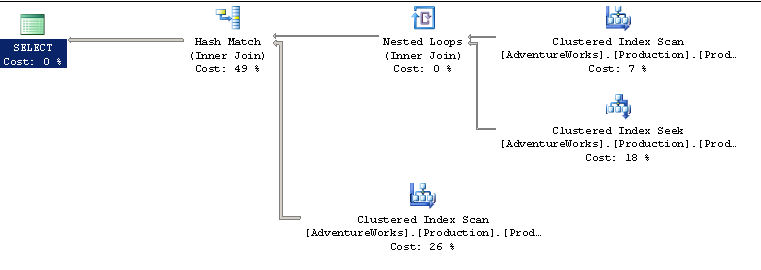
The execution plan is a set of operations in the shape of a tree. It’s read from right to left, with the operations on the far right occurring first as the query runs, proceeding towards the left where there is an operation that constitutes the query (typically select, update, insert, delete or open cursor)
Each of the operators has a set of properties that is visible in a tool tip. These include the names of the physical and logical operations, the number of rows affected, the IO cost, the cpu cost, the number of executions (only in query analyser), the estimated row size and more. The arrows joining the operators also have tool tips, indicating the number of rows and size of the data set
In this case, the first operators executed were a clustered index scan and a clustered index seek (on the far right). These two followed by a nested loop inner join (to join together the result sets) and another clustered index scan. Next a hash match inner join joined together the results of the nested loop join and the last index scan. Finally the rows are returned by the select operator.
That’s a very high level overview. I will go into more detail on bits and pieces of the execution plans in the future. Next up, probably the differences between an estimated execution plan and an actual execution plan, how to get both and when to use them.
It would be really helpful if you could include the link to the next post in this series after every post. 🙂