All you need to know about Columnstore Indexes in one article
I realised the other week, that despite a bunch of posts on indexes over the years, I’ve never written a blog post on Columnstore indexes. Time to fix that. Here’s everything you need to know to get started using columnstore indexes. (Note, this is not, in any way, everything there is to know about columnstore indexes, for that see Nico’s blog series, currently at 131 entries long)
Before I dive into columnstores, for comparison let me first discuss rowstore indexes.
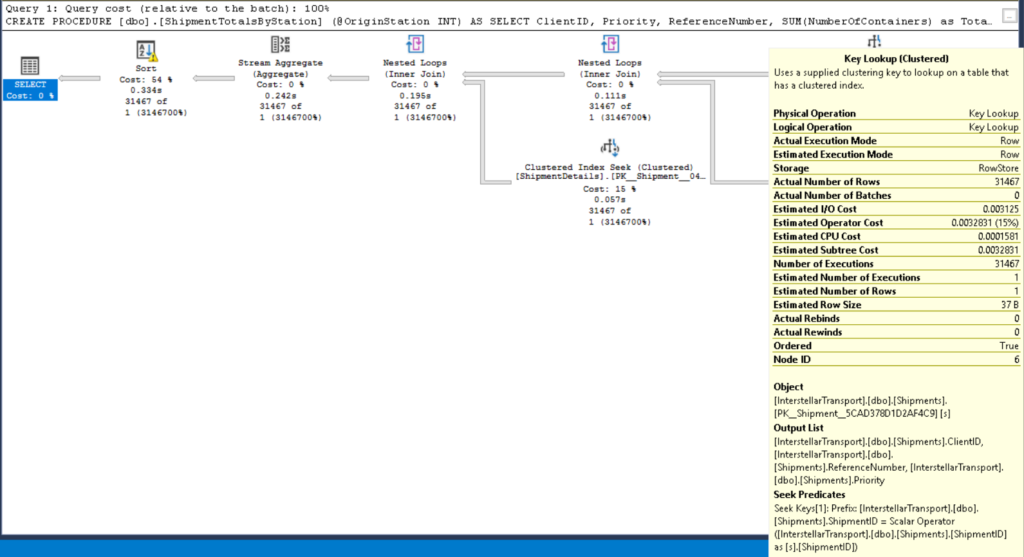
In a rowstore index (what we previously would have just called an index), pages are in a b-tree, the leaf levels containing all the rows and the upper levels containing one row per page below them.
The columns that make up the row (or at least those which are part of the index) are found together in the page. Hence, wanting one column from the index means reading the entire page and all of the other columns that are part of that index.
Columnstores are… different.
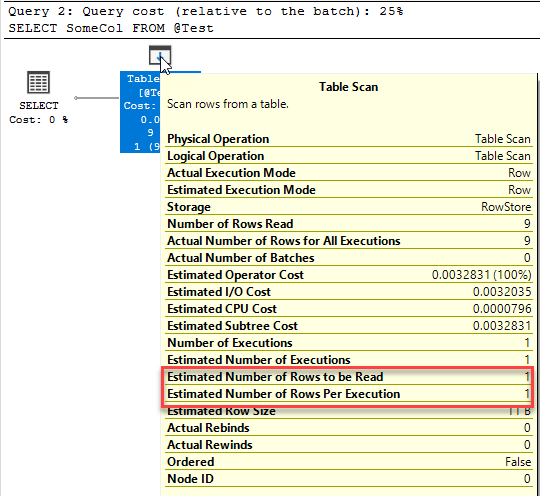
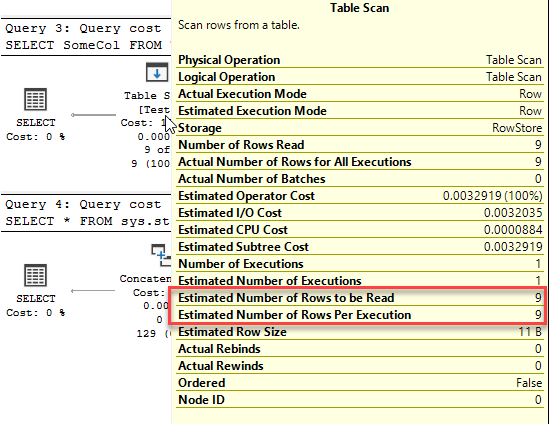
The first, and I would say most important thing to realise about columnstore indexes is that they don’t have keys. These are not seekable indexes. Any access to a columnstore index is going to be a scan.
Instead of storing the rows together on a page, a columnstore index instead stores column values together. The rows in the table are divided into chunks of max a million rows, called a row group, and the columns are then stored separately, in what are called segments. A segment will only ever contain one column’s values.
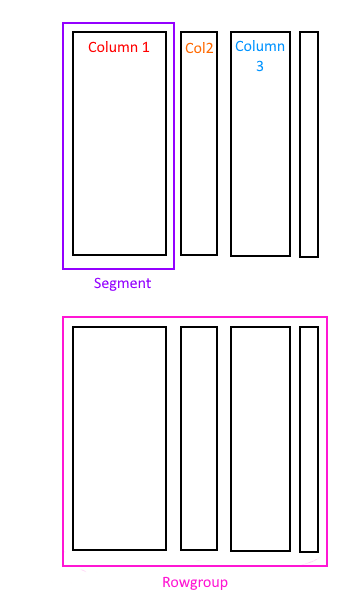
The segments are then compressed, and because typically there will be repeated values in a column, they can compress quite well.
Because of this architecture, if a query needs to get all the values for Column 2 and Column 3, it’s a very efficient access. All of the segments that contain Column 2 and Column 3 can be read, and the segments that contain the other columns can be completely ignored. Conversely, if the query needs all of the columns for a handful of rows, it’s quite an inefficient access. Because there’s no way to seek against a columnstore index, all of the segments would have to be read* to locate the column values that make up the row and the row would have to be reconstructed.
(*) There is a process called rowgroup elimination which can remove row groups from consideration when locating rows. I will not be going into that in this article.
An index of this form is not editable, not easily anyway. The columns are all compressed, so changing a single value could require the entire segment be decompressed before updating a value. The first version of columnstore indexes were indeed readonly, but that made them less than useful in many cases, and so since SQL 2014 columnstore indexes are updatable. Kinda
Well, the compressed segments are not updatable, nor can they be added to, nor can they be deleted from. Directly, that is. Instead what’s done is that new rows are added to something called a ‘delta store’, which is a b-tree index associated with the columnstore. Newly inserted rows are added to this delta store, not to the compressed segments directly. Once the delta store reaches a certain size it’s closed, compressed and the contents are a added to the columnstore index as a new rowgroup. Deletes are handled similarly. When a row is deleted, a flag is set in a deleted bitmap indicating that the row is no longer present. When the index is read, any rows marked deleted in the bitmap are removed from the resultset. Updates are split into deletes and inserts, and hence flag the old version of the row as deleted and then insert the new version of the row into the delta store.
Index rebuild will recreate all of the rowgroups and remove the logically deleted rows, as well as force any open rowgroups to be compressed. Index reorganise operations will force open rowgroups to be compressed and will remove logically deleted rows if more than 10% of the rows in a rowgroup are flagged deleted.
All well and good so far, but why bother? The simple answer here is speed. Columnstore indexes are fast for operations involving large numbers of rows for a couple reasons
- Column-based storage
- Compression
- Batch mode query processing
The first one we’ve already looked at. When a query needs most of the rows in the table but only a few of the columns, the column-based storage is more efficient.
Compression is the second reason. Columnstore indexes are compressed, and because there’s more compression opportunities for column values stored together than rows, they typically compress very well. Good compression means less data which needs to be moved around, which generally translates to better performance
Batch mode used to be the third reason. Batch mode is a query processor feature where multiple rows can be processed at once, rather than one row at a time. It can be a lot faster than row mode. When columnstores were introduced, batch mode was only an option when there was a columnstore index used in the query, but since SQL 2017 batch mode has been available for rowstore indexes as well.
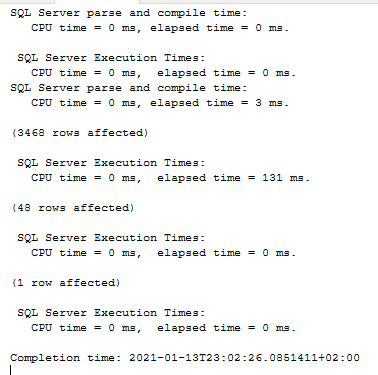
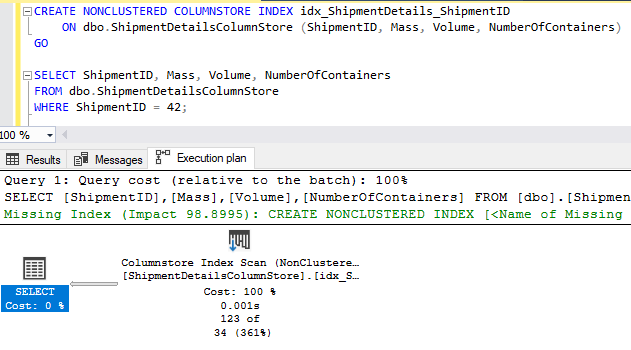
How much faster? Well…
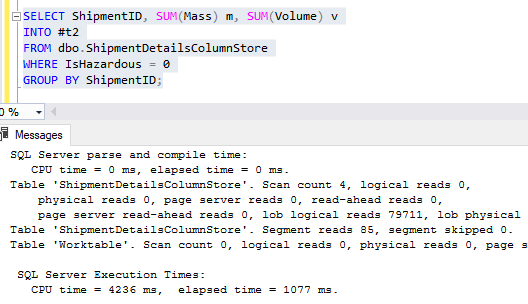
The only difference between the above two queries is that one ran against a table with a rowstore clustered index and one ran against a table with a columnstore clustered index. Oh, and 19 seconds of CPU time. Both tables have exactly the same data in them, 88 million rows.
That’s about all for a high-level overview of columnstore indexes. Of course this isn’t everything there is to know about columnstores, just what you need to know to get started using them. If you want everything, there’s always Nico’s blog series.